https://github.com/utkuozbulak/pytorch-cnn-visualizations
上記のページにある可視化についての紹介が簡単にまとまっていたので、勉強がてら翻訳してみた。
英語読める人は上記のサイトを参考に読んだほうがよいと思う.
敵対的生成に関しては別に分けているらしいので、ここではそれは含まない可視化。
勾配の可視化
| キングスネーク(56) | マスチフ(243) | 蜘蛛(72) | |
| 入力画像 |  |
 |
 |
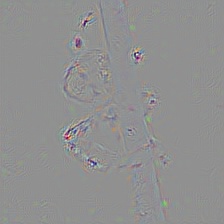
| 色付き生のBackpropagation |  |
 |
 |
| 生のBackpropagation サリエンシ |  |
 |
 |
| 色付きの Guided Backpropagation
(GB) |
 |
 |
 |
| Guided Backpropagation サリエンシ
(GB) |
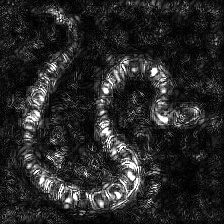 |
 |
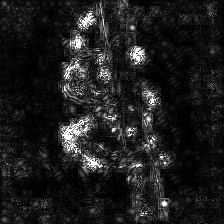 |
| Guided Backpropagation ネガティブなサリエンシ
(GB) |
 |
 |
 |
| Guided Backpropagation ポジティブなサリエンシ
(GB) |
 |
 |
 |
| Gradient-weighted Class Activation Map
(Grad-CAM) |
 |
 |
 |
| Gradient-weighted Class Activation Heatmap
(Grad-CAM) |
 |
 |
 |
| Gradient-weighted Class Activation Heatmap on Image
(Grad-CAM) |
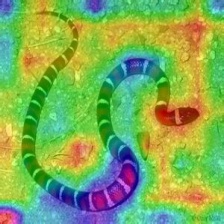 |
 |
 |
| Colored Guided Gradient-weighted Class Activation Map
(Guided-Grad-CAM) |
 |
 |
 |
| Guided Gradient-weighted Class Activation Map Saliency
(Guided-Grad-CAM) |
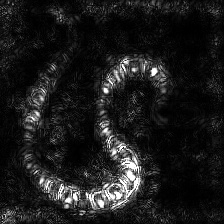 |
 |
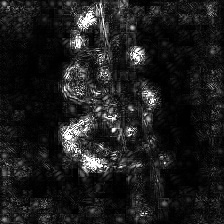 |
Smooth Grad
Smooth Gradは入力画像に幾らかのガウシアンノイズを載せて複数回勾配を計算したのちにその平均をとって可視化画像を生成する。生のBackPropagationとGuided BackPropagationで勾配を生成した例を以下に示す。50回の画像にランダムにノイズを載せている。σをいくらに設定したかは画像の下に記述している。
| Backprop: Vanilla Samples: 50 | ||
 |
 |
 |
| Backprop: Guided Samples: 50 | ||
 |
 |
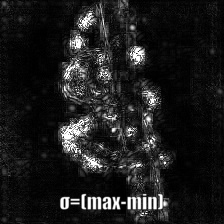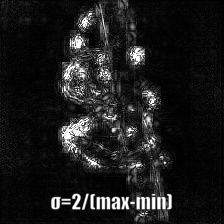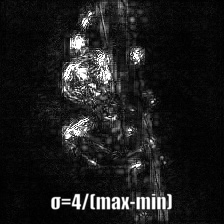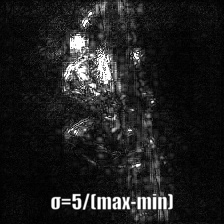 |
Convolutional Neural Network フィルタの可視化
CNNフィルタは特定のConvolution層の出力に応じて入力画像を最適化したときに可視化することができる。以下ではあらかじめ訓練済みのVGG16を使った例を示す。レイヤの可視化は低レイヤの部分では基本的な色と方向フィルタになっている.出力層に近づくにつれて、フィルタの複雑度も増していく。ぼかしや勾配のクリッピングなどの外部技術によってよりまともな画像にすることはできる。
| Layer 2 (Conv 1-2) |
 |
 |
 |
| Layer 10 (Conv 2-1) |
 |
 |
 |
| Layer 17 (Conv 3-1) |
 |
 |
 |
| Layer 24 (Conv 4-1) |
 |
 |
 |
Inverted Image Representations
この技術は今回紹介する中で何をコードがしているかを理解するのが最も複雑かと思われる。その主な原因は複雑な正則化を行うことにある。もし本当にこれらの実装について知りたいのなら論文[5]の2,3ページを読むとよい。特に正則化の部分。ここでの目的は、n番目のレイヤから元画像を生成することにある。モデルの中で深く行けば行くほど、その画像生成をするのは難しくなる。論文の中の結果はかなりよいが、ここでの実装では層を深くしていくほどすぐに画像が乱れてしまう。この違いは論文著者らは各層でパラメータをチューニングしているためです。もしやりたければ、各層の結果を最適化するのに論文で行われているようにパラメータを最適化すればよい。以下は蛇の画像を入力にAlexNetの各層から得られたInvertedサンプルになります。
| Layer 0: Conv2d | Layer 2: MaxPool2d | Layer 4: ReLU |
 |
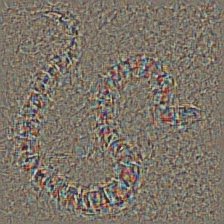 |
 |
| Layer 7: ReLU | Layer 9: ReLU | Layer 12: MaxPool2d |
 |
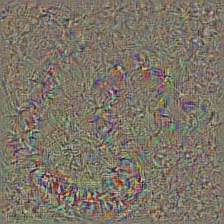 |
 |
Deep Dream
Deep Dreamは層の可視化と技術的には同等のことを行っているが、たった一つの違いは、ランダム画像ではなく実画像を使っている点が異なる.以下の画像はVGG19から生成されていて、生成画像は完全にフィルタに依存するためいちかばちかになる。VGG19よりさらに複雑なモデルはより高次元の特徴量を生成する。もしVGG19をInceptionと置き換えた場合は、抽象度高いConv層をターゲットにしたときにより明らかに特徴的な勾配を得ることができる。層の可視化と同様に、勾配のクリッピングやブラーによって、よりより画像を得ることができる。
| Original Image |  |
| VGG19 Layer: 34 (Final Conv. Layer) Filter: 94 |
 |
| VGG19 Layer: 34 (Final Conv. Layer) Filter: 103 |
 |
クラス指定画像生成
この操作はモデルと適用する正則化に基づいて異なる結果を出力をする。以下では各イテレーションでVGG199で生成した画像にガウシアンブラーを掛けた例。生成された画像の質はモデルに依存する。AlexNetは一般的に緑っぽいものを、VGGはよりよいイメージを生成する。これらは一般的なCNNと最適化された入力画像から作られているのであって、GANから作られたものではないことに注目。
| Target class: Worm Snake (52) – (VGG19) | Target class: Spider (72) – (VGG19) |
 |
 |
正則化方法の方法の違いを知るために注目したクラスの正則化なし,L1,L2の正則化の画像生成を以下に示す。以下ではフラミンゴを注目クラスとしている。これらの画像は訓練済みAlexNetで生成している。
| No Regularization | L1 Regularization | L2 Regularization |
 |
 |
 |
生成されたサンプルはターゲットクラスを生成するためにもっと最適化することができる。(質を上げるには、クリッピングやブラー、ランダムな色のスワップ、幾らかのパートのランダムな画像のクリッピングなどができる)
